
LangChain Indexes: Document Loaders
Dive into the world of LangChain Document Loaders, understand how they work to transform and load text from various sources and learn how to use them in your language modeling tasks.


Welcome to the LangChain introduction series. You can access all the other articles in this series by clicking here.
Language models like GPT-3 have been trained on vast amounts of data, including hundreds of gigabytes and billions of words. As a result, they have a solid foundation of knowledge that enables them to excel in areas such as history and science. However, these models do have limitations. Once they reach a certain point in their training, they cannot absorb any new information unless given access to the internet. Additionally, they don't have access to the vast amounts of data held in private and corporate documents.
Understanding the concept of "Indexes" is crucial in addressing this issue. These indexes help structure documents for easy utilization with LLMs. LangChain offers four tools for creating indexes - Document Loaders, Text Splitters, Vector Stores, and Retrievers. The focus of this article will be Document Loaders.
As the name implies, Document Loaders are responsible for loading documents from different sources. They are versatile tools that can handle various data formats and transform them into a standard structure that language models can easily process.
This guide aims to explain LangChain Document Loaders in-depth, enabling you to make the most of them in your LLM applications.
Understanding LangChain Document Loaders
The first concept to understand is what Langchain calls a Document. It really does not get more straightforward as a Document has two fields:
page_content(string): the raw text of the documentmetadata(dictionary): key/value store of any metadata you want to store about the text (source url, author, etc.)
We’ll look at one of the most basic document loaders (the TextLoader), which opens a text file and loads the text into a Document.
class TextLoader(BaseLoader):
"""Load text files."""
def __init__(
self,
file_path: str,
encoding: Optional[str] = None,
autodetect_encoding: bool = False,
):
"""Initialize with file path."""
self.file_path = file_path
self.encoding = encoding
self.autodetect_encoding = autodetect_encoding
def load(self) -> List[Document]:
"""Load from file path."""
text = ""
try:
with open(self.file_path, encoding=self.encoding) as f:
text = f.read()
except UnicodeDecodeError as e:
# code to handle Decoding errors
except Exception as e:
raise RuntimeError(f"Error loading {self.file_path}") from e
metadata = {"source": self.file_path}
return [Document(page_content=text, metadata=metadata)]
The TextLoader sets the Document page_content to the text of the file, and the metadata stores the “source” file path.
As the source of the data gets more complex you can see that a bit more logic will be needed to create these Documents. At the end of the day our core objective is transforming our data into this standard format for further processing in our Indexing system.
There are three main types of Document Loaders in LangChain: Transform, Public Datasets/Services, Proprietary Datasets/Services
Transform Loaders: Load data from a specific format into the Document format
Transform Loaders are like the TextLoader above - they take an input format and transform it into our Document format. There is a growing list of Transform Loaders in LangChain and includes loaders for:
- CSV
- HTML
- Markdown
- Microsoft Word/PowerPoint
- Notion (raw files or through API integration)
- and many more
Underlying many of these Loaders is the Unstructured Python library. This library is fantastic at transforming a variety of file types into the text data we need for our documents. Understanding how it works will really help you when working with the Loaders.
Unstructured Partitions
The core concept of the Unstructured library is partitioning documents into elements. When passed a file the library will read the source document, split it into sections, categorize those sections, and then extract the text for each section. After partitioning a list of Document Elements is returned.
Here’s what that looks like using the library directly
from unstructured.partition.auto import partition
elements = partition(filename="example-10k.html")
The library uses some tools under the hood to detect the filetype automatically and partition it correctly given the filetype.
Example: Loading Microsoft Word Document
Let’s look at loading a Microsoft Word document to see what it looks like.
Here’s our sample word document
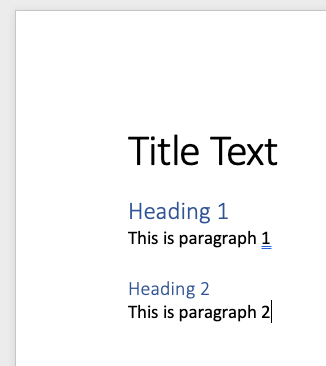
Now we can use LangChain’s UnstructuredWordDocumentLoader to partition the document
from langchain.document_loaders import UnstructuredWordDocumentLoader
# use mode="elements" to return each Element as a Document
# otherwise it defaults the "single" option which returns a single document
loader = UnstructuredWordDocumentLoader(file_path="test_doc.docx", mode="elements")
data = loader.load()
print(data)
Result when using mode="elements", which returns a Document for each Element in the source document
[
Document(page_content = 'Title Text', metadata = {
'source': 'test_doc.docx',
'filename': 'test_doc.docx',
'filetype': 'application/vnd.openxmlformats-officedocument.wordprocessingml.document',
'page_number': 1,
'category': 'Title'
}),
Document(page_content = 'Heading 1', metadata = {
'source': 'test_doc.docx',
'filename': 'test_doc.docx',
'filetype': 'application/vnd.openxmlformats-officedocument.wordprocessingml.document',
'page_number': 1,
'category': 'Title'
}),
Document(page_content = 'This is paragraph 1', metadata = {
'source': 'test_doc.docx',
'filename': 'test_doc.docx',
'filetype': 'application/vnd.openxmlformats-officedocument.wordprocessingml.document',
'page_number': 1,
'category': 'NarrativeText'
}),
Document(page_content = 'Heading 2', metadata = {
'source': 'test_doc.docx',
'filename': 'test_doc.docx',
'filetype': 'application/vnd.openxmlformats-officedocument.wordprocessingml.document',
'page_number': 1,
'category': 'Title'
}),
Document(page_content = 'This is paragraph 2', metadata = {
'source': 'test_doc.docx',
'filename': 'test_doc.docx',
'filetype': 'application/vnd.openxmlformats-officedocument.wordprocessingml.document',
'page_number': 1,
'category': 'NarrativeText'
})
]
Result using the default mode="single", which returns a single Document for all text in the source document
[
Document(
page_content='Title Text\n\nHeading 1\n\nThis is paragraph 1\n\nHeading 2\n\nThis is paragraph 2',
metadata={'source': 'test_doc.docx'}
)
]
You’ll notice that in the “single” mode the elements have been joined using a “\n\n” delimiter. When we cover Text Splitters next this is the default spliter character for the Character splitter.
Public dataset or service loaders: Load data from public datasets or services without the need for access permissions
LangChain provides ready-made Document Loaders for publically available sources to quickly pull in data and create Documents.
There are currently loaders for sites such as Hacker News, Wikipedia, and Youtube Transcripts.
Example: Loading Youtube Transcript
This is a fantastic way to quickly ingest transcripts from Youtube which you could use to summarize or build a database from.
You will need to install the youtube-transcript-api library for it to work and also pytube if you want additional video information like view count, author, and length.
pip install youtube-transcript-api
pip install pytube
To load the transcript you simply need to input the video url
from langchain.document_loaders import YoutubeLoader
loader = YoutubeLoader.from_youtube_url("https://www.youtube.com/watch?v=i70wkxmumAw", add_video_info=True)
transcript_document = loader.load()
This is a Tom Scott video and the result looks like this (I shortened the full transcript for length)
[
Document(
page_content="These days if you want to simulate something\nin the physical world you use a computer. But what if you couldn't? What if it was, say, the 1950s and you needed to work out if a bold but questionable\nplan to dam the San Francisco Bay was a good idea? The answer is this: The US Army Corps of Engineers\nBay Model. The Bay Model is one and a half acres or more. What you're looking at is one of our former\nscientific, hydrodynamic, engineering testing facilities...",
metadata={'source': 'i70wkxmumAw', 'title': 'This giant model stopped a terrible plan', 'description': None, 'view_count': 6249349, 'thumbnail_url': 'https://i.ytimg.com/vi/i70wkxmumAw/hq720.jpg', 'publish_date': datetime.datetime(2016, 12, 1, 0, 0), 'length': 273, 'author': 'Tom Scott'}
)
]
Proprietary dataset or service loaders: Load data from specific formats of applications or cloud services that are not from the public domain
The final type of Document Loaders are for proprietary sources which may require additional forms of authentication or setup to access.
Example: Google Drive
Prerequisites To Enable Access
- Create a Google Cloud project or use an existing one
- Enable the Google Drive API (link should take you automatically to the API enable section)
- Authorize credentials for desktop app
- NOTE: You may need to set up a “Consent” screen first before being able to complete these instructions.
- Don’t worry about what information you input here, just put the minimum amount to get to the next part.
- For Scopes be sure to enable
Google Drive API .../auth/drive - Also make sure to add your email to the “Test users” section to allow access
- This will download a credentials file the loader will need to access your drive
- By default, the
GoogleDriveLoaderexpects acredentials.jsonfile to be located at~/.credentials/credentials.json, but this is configurable using thecredentials_pathkeyword argument
- NOTE: You may need to set up a “Consent” screen first before being able to complete these instructions.
- Install the Google client library
pip install --upgrade google-api-python-client google-auth-httplib2 google-auth-oauthlib
The Drive Loader gives you several options of how to load documents
- By folder id - loads all documents inside folder
- Recursively - will load files from subfolders
- Document id(s) - Loads individual files by given id(s)
- Filter by file types - Allows you to limit what file types you download (e.g. “document”, “sheet”)
By default only “document” file types can be loaded. You will need to enable the Google Sheets API on your project to get access to sheet data.
from langchain.document_loaders import GoogleDriveLoader
loader = GoogleDriveLoader(
folder_id="1PGUjb3lX6PULOae37ukOESbf23uP4HoI",
file_types=["document", "sheet"],
recursive=False
)
docs = loader.load()
When you first run this you will be taken to your browser to authorize the application with your Google Account
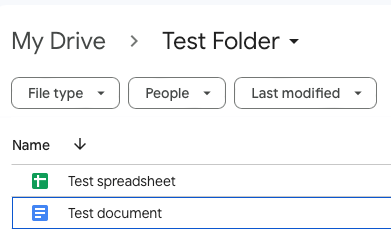
If all goes well you should get an output like this
[
Document(page_content='A1: A2\\nB1: B2\\nC1: C2', metadata={'source': 'https://docs.google.com/spreadsheets/d/1LD2DLpJ4ZRKaIUzzkO3S2rFvVR7FBP4tyNiyb81Ulck/edit?gid=0', 'title': 'Test spreadsheet - Sheet1', 'row': 1}),
Document(page_content='\ufeffThis is a test document', metadata={'source': 'https://docs.google.com/document/d/1TUY0EbRUjoPzPnRK0mVC307LtSULQlBUPRg-80RWheA/edit', 'title': 'Test document'})
]
Wrapping Up
This article has explained what Document Loaders are in LangChain and the basics of how to use them. LangChain provides tools to fetch and transform from various formats and sources meaning you avoid having to write them all yourself for your projects.
Remember, the main purpose is to transform our data from various sources into a structured Document format we can use in the next stages of creating our indexes.
As always, if you have comments or questions, please pop them into the comments below.
To keep up with future posts and support my work, be sure to: