
Introduction to LangChain: A Framework for LLM Powered Applications


In this comprehensive series about LangChain, I will walk through what it is, how it works, and explore the AI-powered applications that can be built with it. In this first post I will explain what LangChain is at a high level and how it can be used.
LangChain helps developers work with LLMs (Large Language Models) like OpenAI’s ChatGPT and GPT-4. LLMs are a language models that use machine learning algorithms and massive amounts of data to analyse and interpret natural language. These models are capable of tasks such as language translation, sentiment analysis, and even generating coherent human-like text. LLMs have become increasingly influential in many fields, including artificial intelligence, natural language processing, and machine learning.
And, oh boy, have they taken the world by storm. Released on November 30th, 2022 it took only 2 months for ChatGPT to reach 100 million users. For comparison, it took Facebook 4 years to achieve the same number of users. It’s not surprising why. Its ability to converse like a human, write and debug code, and even talk like a pirate, represents a step-change in what we thought was possible with an AI system.

But ChatGPT isn’t the only way to interact with LLMs. OpenAI and other providers have released APIs allowing developers to interact directly with these models. And this is where LangChain comes in. LangChain is a software framework to simplify the creation of applications that interact with these models.
In this post, we will explore the unique features of LangChain, including its components and use-case specific chains. We will also discuss the benefits of using LangChain for developing language model-powered applications, such as streamlined development processes, flexibility, customization, and integration with cutting-edge AI and machine learning technologies.
This post gives you a complete summary of LangChain and how it can change how applications using language models work, whether you're an experienced developer or just starting out.
Value Propositions of the LangChain Framework
There are two main value propositions of LangChain
- Components: modular abstractions (think building blocks) for working with language models
- Use-Case Specific Chains: assembly of components tailored for specific use cases
Let’s discuss each in more detail.
Components: Building Blocks of LangChain
There are six main components of LangChain. In future posts, I’ll be exploring each in much greater detail.
Models
LangChain uses three types of models
- LLMs
- The LLM model is designed for interacting with Large Language Models (like GPT-4). It provides a standardised interface so you can interchange different models while keeping the rest of your code the same.
- The LLM model takes a text string input and returns a text string ouput
- Chat Models
- Chat Models use LLMs “under the hood”, but have a different type of interface
- Instead of just “text in, text out”, they use “chat messages” with a more structured interface
- A chat message has the types of “System”, “AI”, or “Human”
- Text Embedding Models
- Embeddings are a concept we’ll dive into much deeper in the future, but grossly simplified, it’s a process that turns text into decimal numbers (called a “vector representation”)
- Once the text is converted to a vector, you can do some very useful things like “semantic search” that returns texts based on how similar they are
- Read the OpenAI guide to embeddings
Prompts
Prompts are our inputs to the model. Think of them like the instructions we want the model to complete, such as “Tell me who the first president of the United States was”.
The art and science of “Prompt Engineering” is its own topic and understanding how to construct a prompt well can have huge impacts on the end result from the model.
LangChain provides several classes and functions for constructing and working with prompts
- Prompt Templates
- These templates allow you to plug in variables, such as specific instructions to the model, the user input, and examples to provide the model with context.
- Example Selectors
- Providing examples to the model can greatly increase the value of its output
- The Example Selector component provides tooling for selecting the best examples to pass to the model based on the user input if you have a large number of examples
- Output Parsers
- Since language models only return text, we often will want to parse the response into structured data.
- Using an Output Parser lets you define the structure you want to format the response into, which you can then more easily pass onto additional steps of the chain
Indexes
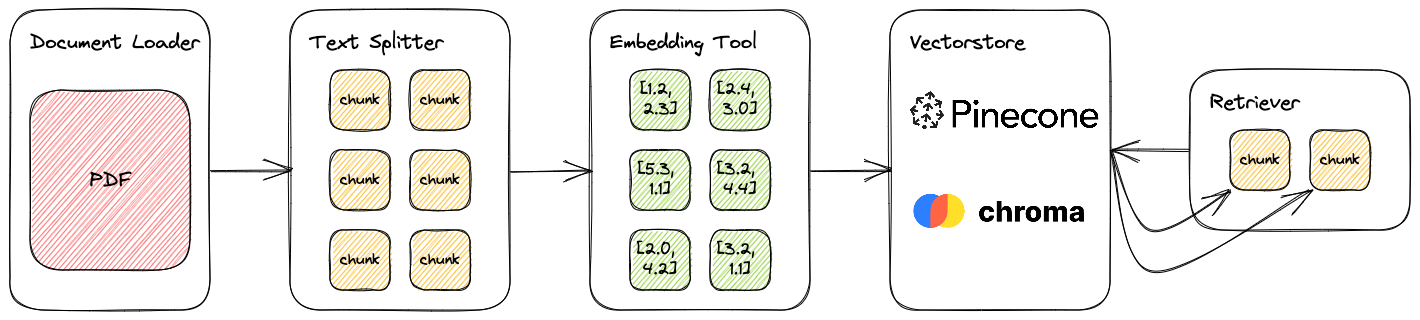
Indexes are how we structure our documents to use them with LLMs more easily. This concept becomes critically important when discussing how to work with large volumes of data that we can’t simply paste into a prompt. Using indexes, we can create a long-term “memory” and retrieval system that allows us to find and select only the most relevant data to send to an LLM due to token limitations.
LangChain breaks this process down into the following sub-components
- Document Loaders
- Tools to ingest and structure data from multiple types of sources (pdf, HTML, markdown, and many more)
- Text Splitters
- Various tools for splitting text into smaller “chunks” that allow us to capture meaning while keeping our input size low
- Vectorstores
- Retrievers
- Once our documents are loaded into our vectorstore LangChain provides different types of “Retrievers” to find relevant documents
- This becomes very important when dealing with large amounts of document data since we cannot simply provide all that data to the LLM - we must condense to avoid character limitations
Memory
LangChain Chains and Agents operate “stateless”, meaning they don’t retain any memory of prior interactions. This is also true of the LLMs they use. So to create that “chat” experience and provide context from earlier parts of the conversation LangChain provides components to store and apply memory.
There are several tools to do this in LangChain, but the basic model is the “Chat Message History”, where you can store user and ai messages and pass them back to the language model as needed.
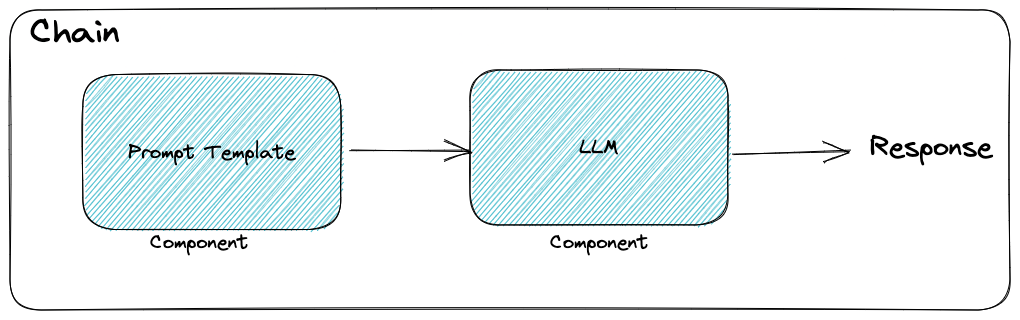
Chains
Chains in LangChain (where the name comes from!) are wrappers around a series of single components. In a basic application, you probably wouldn’t even need to use a chain, but in complex applications involving multiple LLMs (such as when we get to Agents), the Chain component provides a standard interface for interacting with them.
Examples of Chains include:
- LLM chain (simple prompt + response)
- Chat over documents with a chat history
- Question and answers with sources
- API Chains (interact with third-party APIs)
Agents
More recently, LangChain has also introduced the concept of “Agents”: a special chain with access to a suite of tools that can decide which tools to call, depending on the user input. Some applications require an unknown chain that depends on the user's input, and agents can be used to facilitate this process.
LangChain provides the following components for Agents
- Tools: ways for the Agent to interact with the outside world
- Examples included Google Search, Bash, Python REPL, and Zapier
- Agents: LangChain defines different types of agents based on how you want to use it
- For example, a
zero-shot-react-descriptionAgent uses the ReAct (Reason + Act) framework to determine which tool to use based on a description provided
- For example, a
- Toolkits
- These are specialised, pre-built agents designed for a specific purpose
- The “JSON Agent”, for example, is made to interact with large JSON/dict objects to help answer questions about it
- Agent Executor
- This is an Agent + a set of Tools.
- The Executuor runs the following logic:
- calls the agent and is returned the next action + input
- calls the tool required (with input) and is returned the tool’s output
- passes all the information back to the agent to get the next action
If you've heard of AutoGPT, or BabyAGI, this is the model they are running.
Use-Case Specific Chains: Tailored Solutions
The whole purpose of the LangChain framework is to simplify creating applications for a specific use-case. LangChain provides examples and guides for users to build off to accelerate the development process.
Here are the current use-cases LangChain provides:
- Personal Assistants
- Create an Agent with Memory and the ability to use Tools to achieve specific outcomes you set
- The applications for this are essentially infinite.
- Create an “Email Assistant” that checks your inbox and triages messages automatically for you
- Or a “Newsletter Assistant” that finds the latest news articles based on a topic and delivers you a list of the articles, a summary, and a formatted text snippet you can simply insert into your next newsletter
- Question Answering Over Docs
- One of the more powerful use-cases, ingest large amounts of information into an Index and then query it to provide context to an LLM to provide relevant answers
- Chatbots
- Build your own version of “ChatGPT” by providing custom prompts, chat history, and even the ability to interact with other data
- Querying Tabular Data
- A more specialised version of the Question Answering Over Docs, this chain is built to work, especially with tabular data such as csvs, spreadsheets, or SQL data.
- Instead of building SQL queries, you can simply ask, “How many tracks does the artist Grimes have?”
- Interacting with APIs
- Provide an Agent with third-party API documentation and ask a question in natural language (e.g. “What's the weather like in San Franciso”)
- I’m pretty excited by the potential of this use-case, as the ability to interact with APIs unlocks massive opportunities for automation to any product that offers an API
- Summarisation
- Distill long documents down to return the core information
- A common technique for this is to break the documents into smaller chunks, then summarise the chunks recursively until you end up with a single summary chunk
- Extraction
- Related to the “Output Parser” component, Extraction chains take unstructured user data and converts it to structured data
- An example of this is Kor, which uses the case of a user interacting with a music agent and the agent determining what action to take (e.g. “play a track”, “pause”, “provide a list of songs”, etc)
- Evaluation
- More of a meta-use case, LangChain provides tools to help developers evaluate their chains and agents for testing purposes
- To help with testing LangChain has started LangChainDatasets to provide datasets developers can use to test their chains and agents
Advantages of LangChain for Language Model-Powered Applications
Here’s a quick summary of the benefits LangChain provides for developing language model-powered applications.
- Efficient development: LangChain provides powerful building blocks (components) for working with language models, allowing for easy integration and efficient development. The use-case specific chains provide guidance for tailored solutions, making it possible to quickly create applications for a wide range of use cases without extensive knowledge or expertise.
- Adaptability: LangChain's components allow for flexibility and customisation, making it possible to create data-aware and agentic applications that can interact with large amounts of data and provide context to users.
- Integration with the latest AI models: LangChain is designed to work with LLMs like OpenAI's ChatGPT and GPT-4, and continues to develop more integrations as more models come online.
- Ongoing Development and Robust Community: The framework is being worked on continuously with updates nearly daily. The Github repo has 31.8k stars (Apr 2023) and counting. A large and active community is being built around LangChain on Discord where users provide support and share use-cases.
I’ll be writing much more about LangChain in future posts so to keep up and support my work be sure to: