
LangChain Models: Simple and Consistent Interfaces for LLMs, Chat, and Text Embeddings

Welcome to the second part of my introduction series on LangChain. In case you missed it, you can read the first part here: Introduction to LangChain: A Framework for LLM Powered Applications
In this post, I will explore the concept of “Models” in LangChain. Essentially models make it easy to work with different languages or embedding services because they provide a single interface. This means that whether you’re using OpenAI or Hugging Face, you interact with the “model” the same way, making the development and iteration much simpler.
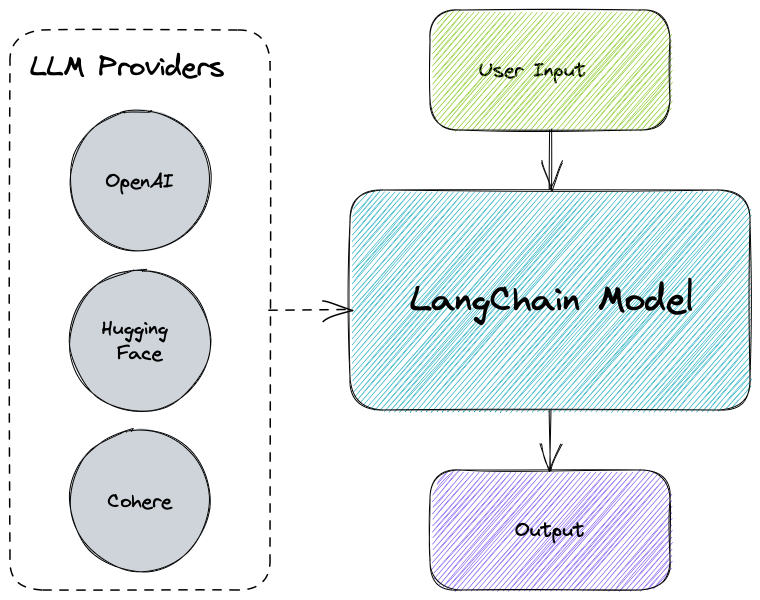
LangChain provides three types of models
- LLMs: Large language models that take a text string as input and return a text string as output
- Chat Models: Models that are usually backed by a language model, but their APIs are more structured
- Text Embedding Models: Models that take text as input and return a list of floats (embeddings)
I will cover each one in detail, explain what they are, how they work, and show some code examples to demonstrate.
LLMs
Large Language Models are quite simple in practice.
You provide a text input in natural language What’s the capital of New Zealand?
and it returns a text responseThe capital of New Zealand is Wellington
As of writing this post, LangChain has integrations with 26 LLMs. Here’s a breakdown.
| LLM | Description |
|---|---|
| AI21 | A platform for building AI applications that comprehend and generate natural language, powered by Jurassic-1 language models |
| Aleph Alpha | A company that develops large-scale language models for the European market |
| Azure OpenAI | A cloud service that provides access to OpenAI’s GPT-3 language model |
| Banana | A platform that helps you build web applications using natural language commands and templates |
| CerebriumAI | A platform that enables data scientists and developers to build and deploy AI solutions faster and easier |
| Cohere | A platform that provides natural language understanding APIs powered by large-scale neural networks |
| DeepInfra | A platform that simplifies the deployment and management of deep learning models on cloud infrastructure |
| ForefrontAI | A platform that helps businesses leverage AI to optimize their operations and customer experiences |
| GooseAI | A platform that provides natural language generation APIs for various domains and use cases |
| GPT4All | A platform that allows anyone to interact with GPT-3 and other language models without coding or API keys |
| Hugging Face Hub | A platform that hosts thousands of pretrained models for natural language processing tasks |
| Hugging Face Local Pipelines | A tool that allows you to run Hugging Face pipelines locally on your machine or server |
| Llama-cpp | A library that provides fast and easy-to-use data structures and algorithms for C++ developers |
| Manifest | A platform that helps you create engaging and interactive content using natural language generation and computer vision |
| Modal | A platform that helps you build conversational AI applications using natural language understanding and dialog management |
| NLP Cloud | A platform that provides high-performance NLP APIs for various tasks such as sentiment analysis, named entity recognition, summarization, etc. |
| OpenAI | A research organization that aims to ensure that artificial intelligence is aligned with humanity’s values and can be widely and safely used by everyone |
| Petals | Petals runs 100B+ language models at home, BitTorrent-style. |
| PipelineAI | A platform that helps you build, train, deploy, and monitor machine learning models at scale on any cloud or edge device |
| PredictionGuard | A platform that helps you monitor and improve the performance of your machine learning models in production |
| PromptLayer OpenAI | A tool that helps you craft effective prompts for OpenAI’s GPT-3 language model using best practices and examples |
| Replicate | A tool that helps you version, package, and share your machine learning experiments with your team or the world |
| Runhouse | A platform that helps you run your machine learning models on any device with a web browser using WebAssembly technology |
| SageMakerEndpoint | A tool that helps you deploy your machine learning models on AWS SageMaker with a few lines of code |
| StochasticAI | A platform that helps you optimize your machine learning workflows using probabilistic programming and Bayesian inference techniques |
| Writer | A platform that helps you create consistent and effective content using generative AI and brand guidelines |
To set up an LLM model, you import it from the langchain.llm module
from langchain.llms import OpenAI
- Note: to use the OpenAI model you’ll also need to install the openai library (
pip install openai)
You then set up the LLM with some basic settings, such as:
model_name- Which model to use- For example, “text-davinci-003” (the default setting), or “text-ada-001”
- These obviously change per llm provider so you will need to review the API documentation for the provider you are using to get the model value
n- The number of completions to create for the given prompt (default is 1)streaming- Whether the results should be “streamed” or not (default is False)- Streaming is when you are returned the results from the LLM piece by piece as opposed to getting the entire result back
- This is useful when developing a Chatbot experience where the text is written out line by line as opposed to in one huge response chunk
temperature- This sets the ‘sampling temperature’ from 0 to 1.- A temperature determines the amount of randomness in the output.
- A temperature of 0 is “precise” and will select the most likely output words. It should always return the same output for a given prompt
- A temperature of 1 is “creative” and will produce different and sometimes surprising results for the same prompt
- The default setting is 0.7 which is still creative but not totally random
llm = OpenAI(model_name="text-davinci-003", n=2, temperature=0.3)
Now that you’ve got the model set up you can use it in a basic input/output
llm("What is the capital of New Zealand?")
# '\\n\\nWellington.'
You can also pass in a list of prompt inputs using the generate function, which produces a richer output that includes information such as the token usage (which can be used for tracking tokens and cost)
llm.generate(["Tell me a riddle", "Tell me a story"])
This will create two lists of “generations” for each prompt input.
Here is an example of a generation:
Generation(
text="\\n\\nQ: What is greater than God,\\nmore evil than the devil,\\nthe poor have it,\\nthe rich need it,\\nand if you eat it, you'll die?\\n\\nA: Nothing",
generation_info={'finish_reason': 'stop', 'logprobs': None}
)
And the llm_output looks like this:
{
'token_usage':
{
'completion_tokens': 254,
'prompt_tokens': 9,
'total_tokens': 263
},
'model_name': 'text-davinci-003'
}
Another useful function is get_num_tokens that estimate how many tokens and piece of text contains, which can be used when needing to keep total tokens under a set limit or budget.
llm.get_num_tokens("What is the capital of New Zealand?")
# 8
- Note: This requires the tiktoken library to estimate, so it needs to be installed to use (
pip install tiktoken)
LangChain also provides the following guides for implementing different functionalities with the LLM models:
- How to use the async API for LLMs
- How to write a custom LLM wrapper
- How (and why) to use the fake LLM
- How to cache LLM calls
- How to serialize LLM classes
- How to stream LLM and Chat Model responses
- How to track token usage
Chat Models
Chat models operate using LLMs but have a different interface that uses “messages” instead of raw text input/output. LangChain provides functionality to interact with these models easily.
With a Chat Model you have three types of messages:
- SystemMessage - This sets the behavior and objectives of the LLM. You would give specific instructions here like, “Act like a Marketing Manager.” or “Return only a JSON response and no explanation text”
- HumanMessage - This is where you would input the user’s prompts to be sent to the LLM
- AIMessage - This is where you store the responses from the LLM when passing back the chat history to the LLM in future requests
There is also a generic ChatMessage that takes an arbitrary “role” input that can be used in a situation that requires something other than System/Human/AI. But in general, you’ll use the three types above.
To use, you need to import the chat model for the integration you are using
from langchain.chat_models import ChatOpenAI
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
Then you initialize the chat agent. This example uses the OpenAI chat model
chat = ChatOpenAI(temperature=0)
Like the LLM model, this also has multiple settings that can be adjusted, such as:
model- Default is “gpt-3.5-turbo”temperature- See the explanation abovemax_tokens- Sets a limit on the number of tokens the LLM should generate in the response
You will then pass in a list of messages to the chat agent to generate responses. In a future article about LangChain “Memory” we will discuss the ChatMessageHistory class that is used to store and apply the chat history which creates that “conversation” benefit of the agent remembering the context of the chat and using it in future responses.
messages = [
SystemMessage(content="Return only a JSON object as a response with no explanation text"),
HumanMessage(content="Generate a JSON response object containing a brief description and release year for the movie 'Inception'")
]
chat(messages)
# AIMessage(content='{\\n "title": "Inception",\\n "description": "A skilled thief is given a final chance at redemption which involves executing his toughest job yet: Inception. The idea of planting an idea into someone\\'s mind is deemed impossible by most, but Cobb and his team of specialists must accomplish this task to save their lives.",\\n "release_year": 2010\\n}', additional_kwargs={})
The Chat Model, like the LLM Model, also has a generate function where you can pass in multiple sets of messages. Like above it also includes useful information like token usage.
batch_messages = [
[
SystemMessage(content="Return only a JSON object as a response with no explanation text"),
HumanMessage(content="Generate a JSON response object containing a brief description and release year for the movie 'Inception'")
],
[
SystemMessage(content="Return only a JSON object as a response with no explanation text"),
HumanMessage(content="Generate a JSON response object containing a brief description and release year for the movie 'Avatar'")
]
]
result = chat.generate(batch_messages)
print(result.generations[1])
# ChatGeneration(text='{\\n "title": "Avatar",\\n "description": "A paraplegic marine dispatched to the moon Pandora on a unique mission becomes torn between following his orders and protecting the world he feels is his home.",\\n "release_year": 2009\\n}', generation_info=None, message=AIMessage(content='{\\n "title": "Avatar",\\n "description": "A paraplegic marine dispatched to the moon Pandora on a unique mission becomes torn between following his orders and protecting the world he feels is his home.",\\n "release_year": 2009\\n}', additional_kwargs={}))
print(result.llm_outout)
# {'token_usage': {'prompt_tokens': 91, 'completion_tokens': 151, 'total_tokens': 242}, 'model_name': 'gpt-3.5-turbo'}
Prompt Templates
We won't be hardcoding our prompts when building dynamic, user-facing applications. We need to be able to construct prompts using user input inside of our prompt templates. LangChain provides classes to construct these prompt templates and dynamically insert inputs.
Prompt Templates allow you to pass in variable values to dynamically adjust what is passed to the LLM.
Here is an example from the documentation:
from langchain.prompts.chat import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
...
system_template="You are a helpful assistant that translates {input_language} to {output_language}."
system_message_prompt = SystemMessagePromptTemplate.from_template(system_template)
# SystemMessagePromptTemplate(prompt=PromptTemplate(input_variables=['input_language', 'output_language'], output_parser=None, partial_variables={}, template='You are a helpful assistant that translates {input_language} to {output_language}.', template_format='f-string', validate_template=True), additional_kwargs={})
human_template="{text}"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
# HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=['text'], output_parser=None, partial_variables={}, template='{text}', template_format='f-string', validate_template=True), additional_kwargs={})
chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])
# ChatPromptTemplate(input_variables=['output_language', 'input_language', 'text'], output_parser=None, partial_variables={}, messages=[SystemMessagePromptTemplate(prompt=PromptTemplate(input_variables=['input_language', 'output_language'], output_parser=None, partial_variables={}, template='You are a helpful assistant that translates {input_language} to {output_language}.', template_format='f-string', validate_template=True), additional_kwargs={}), HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=['text'], output_parser=None, partial_variables={}, template='{text}', template_format='f-string', validate_template=True), additional_kwargs={})])
# get a chat completion from the formatted messages
chat(chat_prompt.format_prompt(input_language="English", output_language="French", text="I love programming.").to_messages())
# AIMessage(content="J'adore la programmation.", additional_kwargs={})
Under the hood, LangChain is using the built-in string library’s Formatter class to parse the template text using the passed in variables. That’s why the variables in the template have the curly braces ({}) around them.
Here’s an example of what is happening to the template.
from string import Formatter
formatter = Formatter()
format_string = "Hello, {name}! You are {age} years old."
result = formatter.format(format_string, name="John", age=30)
print(result) # Output: "Hello, John! You are 30 years old."
LangChain provides a couple of guides on ChatModels:
- How to use few shot examples
- “Few-Shot Prompting” is a technique where you provide the LLM with examples of expected responses within your prompt to “condition” the LLM on how to respond
- How to stream responses
- With streaming you can display the response text as you receive it from the LLM without having to wait for the entire response. It definitely adds to the “chat” experience.
Text Embedding Models
The topic of how Embedding works really deserves its own post but let’s go over the basic concepts and explore the tools LangChain provides to work with them.
Embeddings are a way to turn words, phrases, or sentences into fixed-size number lists in natural language processing (NLP). This helps algorithms better understand and work with text data by turning them into a numerical form (called a “vector”). Embeddings show the meaning and structure of words, and similar words have similar embeddings.
Once we have converted words into these “vectors” mathematical methods can be used to calculate the similarity or differences between words. This has proven incredibly powerful and is why the latest LLMs have been vastly more useful than previous systems.
Here's a high-level example of converting the sentence "This is how embeddings work" into embeddings.
Tokenize the sentence into words: ["This", "is", "how", "embeddings", "work"]
Convert each word into its corresponding embedding vector using a pre-trained embedding model. Each vector is typically represented as a fixed-length array of floating-point numbers:
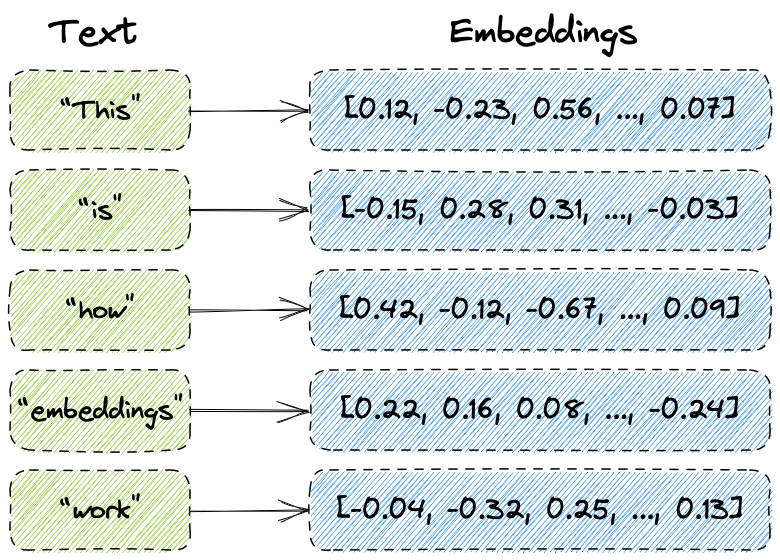
The sentence "This is how embeddings work" can now be represented as a sequence of embedding vectors:
[
[0.12, -0.23, 0.56, ..., 0.07],
[-0.15, 0.28, 0.31, ..., -0.03],
[0.42, -0.12, -0.67, ..., 0.09],
[0.22, 0.16, 0.08, ..., -0.24],
[-0.04, -0.32, 0.25, ..., 0.13]
]
Once you have the sequence of vectors, you can run queries like semantic searches to return the most relevant results (we will be exploring in future posts about Q&A document chains!)
LangChain currently offers integrations for the following providers:
- Aleph Alpha
- AzureOpenAI
- Cohere
- Fake Embeddings
- Hugging Face Hub
- InstructEmbeddings
- Jina
- Llama-cpp
- OpenAI
- SageMaker Endpoint Embeddings
- Self Hosted Embeddings
- Sentence Transformers Embeddings
- TensorflowHub
Let’s look at using the Sentence Transformers Embeddings, which can be installed locally and originates from Sentence-BERT.
First install the package
pip install sentence_transformers
from langchain.embeddings import HuggingFaceEmbeddings, SentenceTransformerEmbeddings
embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
# Equivalent to SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
text = "This is how embeddings work."
query_result = embeddings.embed_query(text)
doc_result = embeddings.embed_documents([text, "This is not how embeddings work."])
- The difference between
embed_queryandembed_documentsis thatembed_querytakes just a single string as input whileembed_documentstakes a list of strings.
Now if you review the output from embeddings, you’ll notice it returns a single list of embeddings for each string and not a list of embeddings per word in each string like in my example above. This is because the embedding is done on the entire sentence and allows for comparisons at the sentence level, not the word/token level.
Wrapping Up
Phew! We covered a lot in the post today but have hardly scratched the surface of what is possible.
We covered the three “Models” LangChain uses (LLMs, Chat, and Text Embeddings), and showed the basics of how they work in practice. We will explore each in more detail in future posts as we dive into how and where they are used when building applications.
As always, if you have comments or questions, please pop them into the comments below.
To keep up with future posts and support my work, be sure to: